Hello everyone,
I am looking for a technical DSP / loudspeaker-measurement sanity check on one specific physical chain.
This is not a product pitch, and I am not asking for endorsement. I am trying to verify whether the following representation is physically and mathematically reasonable before building anything larger on top of it.
The chain is:
Z(f) → Y(f)=1/Z(f) → y(t)=IFFT(Y(f))<br>
where Z(f) is a complex loudspeaker electrical impedance model, Y(f) is admittance, and y(t) is then used as a convolution kernel on a voltage signal:
i(t) = fftconvolve(v(t), y(t))<br>
The intended interpretation is:
The impedance model is a lumped-element TS-parameter model:
with n = 0.6.
The FFT setup is:
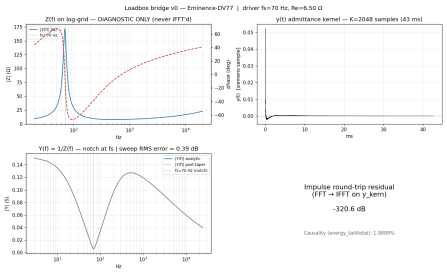
Also, the n = 0.6 lossy inductance model is not strictly causal in the IFFT sense. The full IFFT shows around 1.6–2% wrap-around / tail energy. I have kept this as a warning rather than hiding it, because it may be a real modelling issue rather than an implementation bug.
This is also not:
A short pointer to one broken assumption would be more useful than a broad review.
Thank you.
I am looking for a technical DSP / loudspeaker-measurement sanity check on one specific physical chain.
This is not a product pitch, and I am not asking for endorsement. I am trying to verify whether the following representation is physically and mathematically reasonable before building anything larger on top of it.
The chain is:
Z(f) → Y(f)=1/Z(f) → y(t)=IFFT(Y(f))<br>
where Z(f) is a complex loudspeaker electrical impedance model, Y(f) is admittance, and y(t) is then used as a convolution kernel on a voltage signal:
i(t) = fftconvolve(v(t), y(t))<br>
The intended interpretation is:
So this is not treating impedance as an audio EQ curve.given an applied voltage v(t), the output i(t) is the current that would flow through the equivalent loudspeaker impedance.
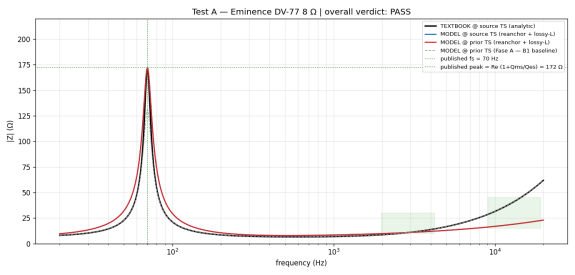
Current test case
I am using an Eminence DV-77 8 Ω as a reference driver.The impedance model is a lumped-element TS-parameter model:
- motional branch from published fs, Re, Qms, Qes
- HF voice-coil behaviour modelled as a semi-inductive lossy term:
with n = 0.6.
The FFT setup is:
- sample rate: 48 kHz
- FFT size: 16384
- linear FFT grid, not log-spaced
- complex Hermitian-symmetric spectrum
- no magnitude-only IFFT shortcut
- outer 5% cosine taper on the one-sided spectrum
- final kernel truncated to 2048 samples with a short Hann tail
Internal checks so far
The implementation currently passes these checks:- Y(0) ≈ 1/Re
- Z(f) peak occurs near fs
- Y(f) notch occurs near fs
- for the DV-77, modelled peak |Z| ≈ 171.9 Ω at about 70.3 Hz, matching the analytic TS prediction:
- sweep recovery: applying the kernel to a log sweep and estimating |I(f)/V(f)| recovers |Y(f)| within roughly 0.3–0.4 dB RMS over the main checked range
- FFT/IFFT round-trip residual is at numerical floor
- Re(Z(f)) ≥ 0 over the frequency range
Important caveats
The chain has not yet been validated against a measured impedance curve from a physical speaker. So far, the main “reality” check is the analytic TS-derived impedance peak for one driver.Also, the n = 0.6 lossy inductance model is not strictly causal in the IFFT sense. The full IFFT shows around 1.6–2% wrap-around / tail energy. I have kept this as a warning rather than hiding it, because it may be a real modelling issue rather than an implementation bug.
This is also not:
- an amplifier model
- a tube output stage model
- an output transformer model
- an acoustic cabinet simulator
- a nonlinear / thermal model
- a real-time implementation
Questions
I would appreciate any critique on these specific points:- Is y(t)=IFFT(1/Z(f)) the right primitive if the input is voltage and the desired output is current?
- Would you instead use another representation for this kind of problem, such as direct ODE/network integration, ABCD matrices, state-space, or minimum-phase reconstruction?
- Is n = 0.6 a defensible default for lossy voice-coil inductance in guitar/loudspeaker modelling, or is there a better standard starting point?
- If you were validating this against one physical speaker on a bench, what measurement would you run first to falsify the approach quickly?
- Are there obvious pitfalls here around causality, sampling, phase, or voltage/current interpretation that I am likely missing?
A short pointer to one broken assumption would be more useful than a broad review.
Thank you.